{kind=link}

This README is also available in English!
| 🪧 Vitrine.Dev | |
|---|---|
| ✨ Nome | Challenge Data Science |
| 🏷️ Tecnologias | Python, Machine Learning, Data Science |
| 🚀 URL | https://bit.ly/38vJKUG |
| 🔥 Desafio | https://www.alura.com.br/challenges/data-science/ |
O desafio consiste em assumir o papel de um novo cientista de dados contratado na Alura Voz. Essa empresa fictícia está no setor de telefonia e precisa reduzir a taxa de evasão, também chamada de Churn Rate.
Na primeira semana, o objetivo é limpar o conjunto de dados fornecido por uma API. Em seguida, precisamos identificar os clientes com maior probabilidade de sair da empresa, usando análise de dados, depois a ideia é usar modelos de aprendizado de máquina para prever a taxa de evasão e orientar o processo de tomada de decisão da Alura Voz.
O conjunto de dados está disponível em um arquivo JSON, à primeira vista parecia uma tabela normal.
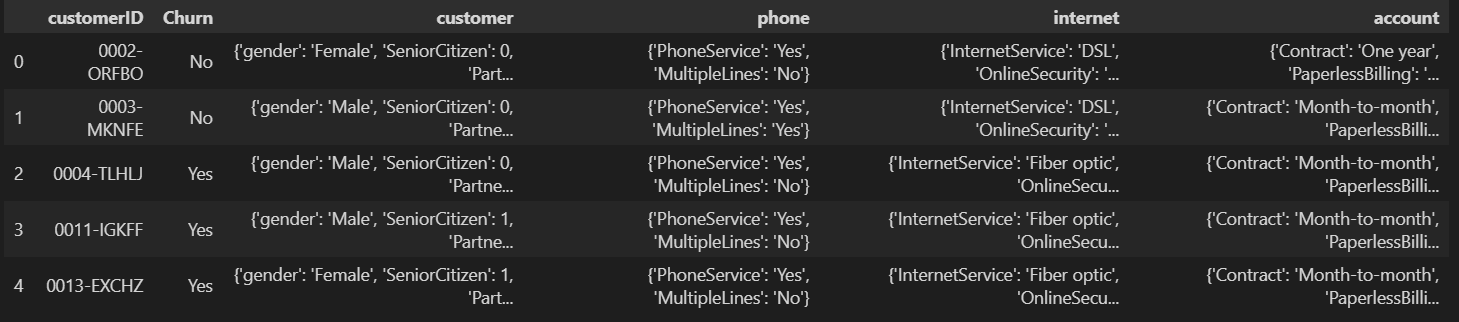
Mas, como podemos ver, customer, phone, internet e account são tabelas próprias no formato JSON. Então é necessário normalizá-las separadamente e depois concatenar todas essas tabelas em uma.
A primeira vez que procurei por dados faltantes no conjunto de dados, notei que, aparentemente, não havia nada faltando, mas ao investigar mais profundamente percebi que havia espaço vazio e também apenas espaço não sendo contado como NaN. Então eu corrigi isso, e agora o conjunto de dados tinha 224 valores ausentes para Churn e 11 faltantes para Charges.Total.
customerID 0
Churn 224
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
Charges.Monthly 0
Charges.Total 11
dtype: int64
Resolvi deixar de lado o Churn que faltava porque este será o objeto de nosso estudo e não adianta estudar algo que não existe. Para o Charges.Total ausente, acredito que representa um cliente que ainda não pagou nada, então apenas substituí o valor ausente por 0.
O recurso SeniorCitizen foi o único que veio com 0 e 1 em vez de Yes e No. Por enquanto, estou alterando para Yes e No, porque facilitará a leitura da análise.
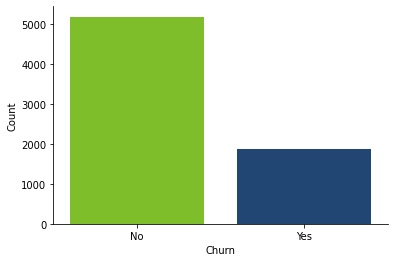
No primeiro gráfico, podemos ver o quanto nosso conjunto de dados está desbalanceado. São mais de 5.000 clientes que não saíram da empresa e pouco menos de 2.000 que saíram.
Também gerei 16 gráficos para todos os dados discretos. Eu queria ver se havia algum comportamento que tornasse alguns clientes mais propensos a deixar a empresa. Para ver todos os gráficos veja o notebook da pasta 2 - Data Analysis.
É fácil ver que todos, exceto o gender, parecem ter um papel em determinar se um cliente deixará a empresa ou não. Mais especificamente, métodos de pagamento, contratos, backup online, suporte técnico e serviço de internet.
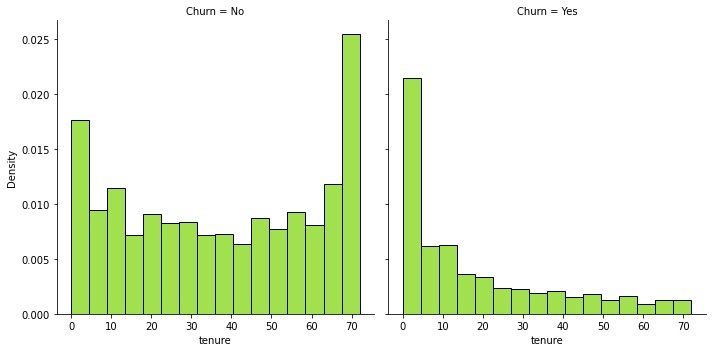
No gráfico de tenure, decidi fazer um gráfico de distribuição para a tenure, um gráfico para clientes que não deixaram a empresa e um para clientes que deixaram. Podemos ver que os clientes que deixaram a empresa tendem a fazê-lo no início de seu tempo na empresa.
A mensalidade média dos clientes que não se desligaram é de 61,27 unidades monetárias, enquanto os clientes que se desligaram pagavam 74,44. Isso provavelmente se deve ao tipo de contrato que eles escolheram, mas de qualquer forma, sabe-se que preços mais altos afastam o cliente.
Considerando tudo o que pude ver através de parcelas e medidas, criei um perfil para clientes com maior probabilidade de evasão.
-
Novos clientes são mais propensos a evadir do que clientes mais antigos.
-
Clientes que utilizam menos serviços e produtos tendem a deixar a empresa. Além disso, quando não estão vinculados a um contrato mais longo, parecem mais propensos a desistir.
-
Em relação à forma de pagamento, os clientes que saem têm uma preferência forte por cheques eletrônicos e costumam gastar 13,17 unidades monetárias a mais do que o cliente médio que não saiu.
Começamos fazendo variáveis dummies descartando a primeira, então teríamos n-1 dummies para n categorias. Em seguida, passamos a observar a correlação de features.
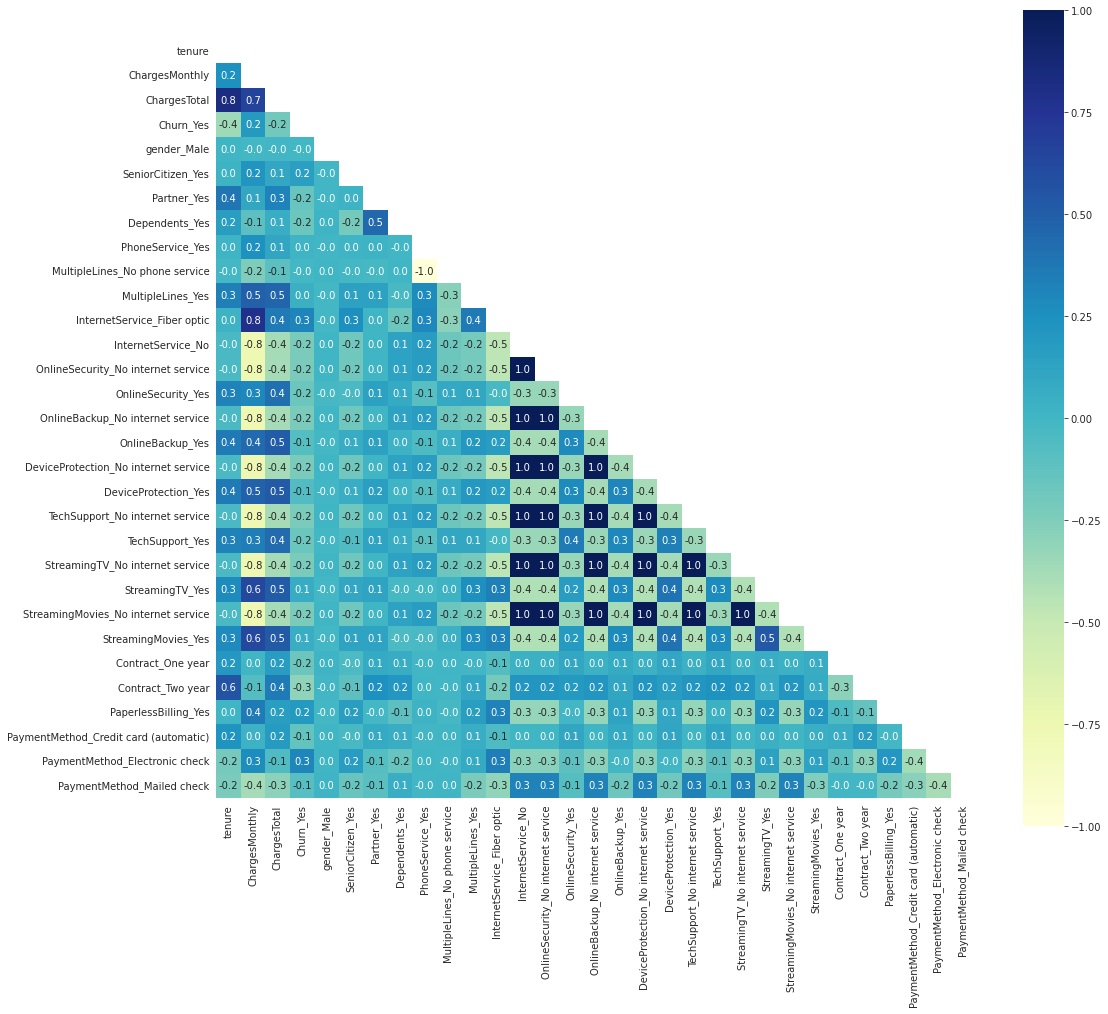
Podemos ver que a feature InternetService_No tem muitas correlações fortes com muitos outros recursos, porque esses outros recursos dependem do cliente ter serviço de internet. Então, vou descartar todos os recursos que dependem disso. A mesma coisa acontece com PhoneService_Yes.
tenure e ChargesTotal também possuem uma forte correlação, mas vou executar os modelos com esses dois, pois acho que ambos são relevantes.
Depois de descartar esses recursos, sigo com a normalização dos dados numéricos, ChargesTotal e tenure.
Como o conjunto de dados é desequilibrado, depois de dividir o conjunto de dados entre os conjuntos de treinamento e teste, farei uma superamostragem do conjunto de treinamento usando a técnica SMOTE.
Usarei um classificador dummy para ter um modelo de base (também chamado de baseline) para a pontuação de acurácia e também usarei as métricas: precisão, recall e pontuação f1. Embora o modelo dummy não tenha valores para essas métricas, vou mantê-lo para comparação de quanto os modelos melhoraram.
Eu fiz o modelo baseline usando um classificador dummy que adivinhou que todos os clientes se comportavam da mesma forma. Supõe-se sempre que nenhum cliente sairá da empresa. Ao usar essa abordagem, obtivemos uma pontuação de acurácia de 0,73456.
Todos os modelos que avançam terão o mesmo estado aleatório.
Começo usando grid search com validação cruzada para encontrar os melhores parâmetros dentro de um determinado conjunto de opções usando o recall como estratégia para avaliar o desempenho. O melhor modelo foi:
RandomForestClassifier(criterion='entropy', max_depth=5, max_leaf_nodes=70, random_state=22)Depois de ajustar este modelo, as métricas de avaliação foram:
- Pontuação de acurácia: 0,72534
- Pontuação de precisão: 0,48922
- Pontuação de recall: 0,78877
- Pontuação F1: 0,60389
Para este modelo, usei apenas os parâmetros padrão e defini o teto para o máximo de iterações para 900000.
LinearSVC(max_iter=900000, random_state=22)Depois de ajustar este modelo, as métricas de avaliação foram:
- Pontuação de acurácia: 0,71966
- Pontuação de precisão: 0,48217
- Pontuação de recall: 0,75936
- Pontuação F1: 0,58982
Aqui eu fixei o solver para LBFGS e usei a grid search com validação cruzada para encontrar um tamanho de camada oculta que seria o melhor. O melhor modelo foi:
MLPClassifier(hidden_layer_sizes=(1,), max_iter=9999, random_state=22, solver='lbfgs')Depois de ajustar este modelo, as métricas de avaliação foram:
- Pontuação de acurácia: 0,72818
- Pontuação de precisão: 0,49133
- Pontuação de recall: 0,68182
- Pontuação F1: 0,57111
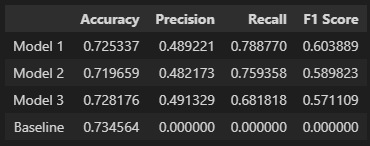
Eu rodei três modelos, todos eles usando o mesmo random_state. O primeiro modelo foi uma floresta aleatória, com max_depth = 5 e max_leaf_nodes = 70. Eu usei grid search com validação cruzada em alguns parâmetros aleatórios para encontrar essa combinação e recall como a estratégia de avaliação para a validação cruzada. O segundo modelo é um SVC linear simples. E por último, o terceiro modelo é uma rede neural com um perceptron multicamada, neste caso, também usei grid search com validação cruzada com o solver LBFGS em algumas camadas ocultas de tamanhos aleatórios e recall como a estratégia de avaliação para a validação cruzada. No final, a Floresta Aleatória teve as melhores métricas em geral.
Na última semana, devemos trabalhar no portfólio e no storytelling dos dados. Eu escrevi um post no meu site que você pode ler mais sobre isso aqui.