Backend
[Em construção]
A princípio, o backend está modularizado da seguinte forma:
-
crawlers: Implementa a lógica responsável por controlar os spiders, bem como download de páginas e arquivos de uma coleta. Alguns módulos a se destacar:
- FileDowloader: Executa em paralelo e é responsável por organizar e baixar arquivos descobertos durante a coleta.
-
FileDescriptor: Ao baixar um arquivo,
FileDownloadergera uma descrição do que foi baixado, como seu link e formato, entãoFileDescriptor, que também executa em paralelo, persiste essa informação.
-
interface: Contempla a estrutura base do
Djangopara implementar a interfaceWebda plataforma. - main: Responsável pela lógica da API e interface Web, como suas rotas, modelos base do projeto e serializadores deles.
- src: Possui submódulos que permitem funcionalidades extras ao sistema.
-
tests: Testes para cada um dos submódulos em
src.
O backend está estruturado da seguinte forma:
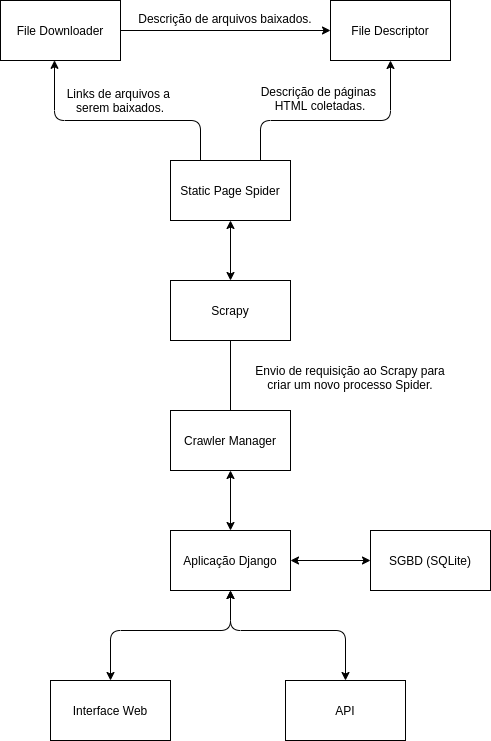
O esquema abaixo detalha o processo de execução de uma coleta:
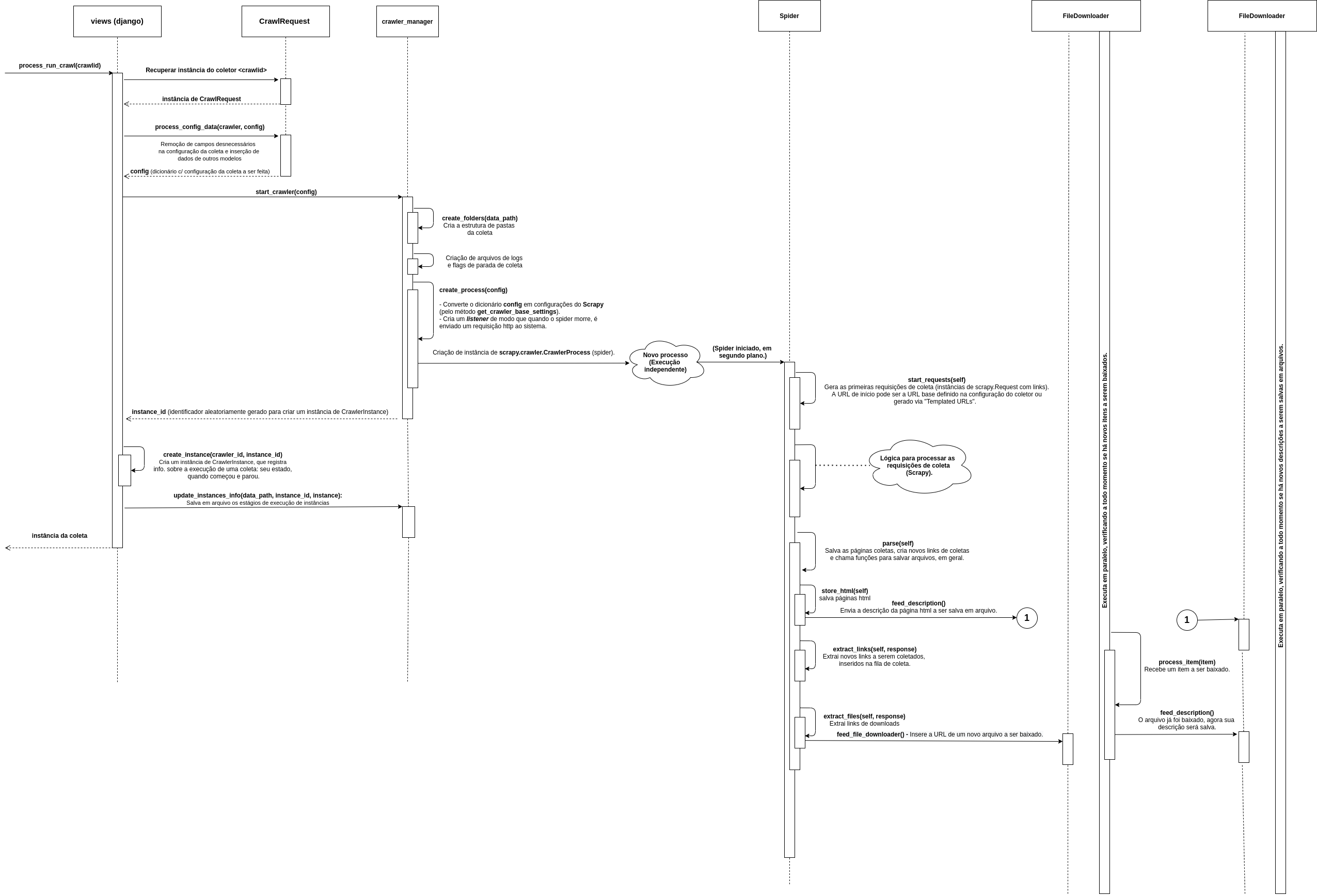
Uma requisição HTTP para o endereço http://localhost:8000/detail/run_crawl/<crawlid>, onde crawlid é um identificador para uma configuração de um coletor. A requisição é recebida em interface/urls, que a encaminha para main/urls.
Em main/urls, é linkado que o endereço HTTP em questão deverá ser processado pelo método views/run_crawl, que, por sua vez, encaminha o processamento para o método views/process_run_crawl, representado no diagrama acima. Após todo o processo de execução no método, é retornado uma resposta HTTP, redirecionando o usuário para a página de detalhes da coleta crawlid.
A classe estática BaseMessenger é crawlers.base_messenger.BaseMessenger. Está sendo utilizada enquanto a integração com Kafka e Scrapy-Cluster não estiver sido realizada.
Executa operações sobre arquivos e serve de base para FileDownloader e FileDescriptor, oferecendo métodos para parar sua execução, adicionar e listar itens a serem processados por eles (para serem baixador por FileDownloader ou ter descrições salvas em FileDescriptor).
Método estático responsável por criar um arquivo contendo informações para serem processadas pelas classes filhas de BaseMessenger. Isto é, conteúdo para realização do download ou gerar a descrição de um arquivo baixado.
@staticmethod
def feed(address, content)Parâmetros:
- address (str) - endereço da pasta onde o arquivo gerado será armazenado.
-
content (dict) - serializável
jsoncom dados para serem processados pelas classes filhas.
Método estático responsável por enviar o sinal de parada para instância em execução, alterando o valor de uma flag em um arquivo de controle.
@staticmethod
def stop_source(address):Parâmetros
-
address (str) - endereço da pasta onde está o arquivo de controle
flags.json.
Método estático responsável por criar um iterator de itens a serem processados pelas classes filhas, que foram inseridos pelo método feed.
@staticmethod
def source(address, testing=False):Parâmetros
- address (str) - endereço da pasta que contém os novos itens a serem processados pelas classes filhas.
-
testing (bool) - parâmetros para debugging, não usar (default
False).
Herda de BaseMessenger.
A classe estática FileDownloader é crawlers.file_downloader.FileDownloader e é responsável por executar o download de arquivos descobertos durante uma coleta.
Método estático responsável por inserir um link de arquivo recém descoberto para a fila de coleta.
@staticmethod
def feed_downloader(url, destination, description)Parâmetros:
- url (str) - url do arquivo a ser baixado.
- destination (str) - endereço da pasta que o arquivo ficará.
- description (dict) - metadado contendo uma descrição do item a ser baixado.
Método estático que envia o sinal para que a instância do FileDowloader pare sua execução.
@staticmethod
def stop_downloader_source()Método estático responsável por criar um iterator de itens a serem baixados.
@staticmethod
def download_source(testing=False)Parâmetros:
-
testing (bool) - parâmetro para debugging (default
False).
Método estático que converte arquivos do tipo PDF em CSVs, os salvando com suas respectivas descrições.
@staticmethod
def convert_binary(item)Parâmetros:
- item (dict) - possui a descrição de um item baixado, como o local onde foi armazenado.
Método estático responsável por efetivamente executar o download de um arquivo.
Arquivos grandes, maiores que 1e9 bytes, são baixados pelo método download_large_file, e os demais por download_small_file.
@staticmethod
def process_item(item)Parâmetros:
- item (dict) - possui dados com as informações necessárias para baixar um arquivo, como sua url e sua origem.
Método estático que executa em um processo separado, sendo a responsável por iniciar as threads que executam internal_consumer, downloads_waiting_crawl_end e internal_producer.
Cria as variáveis wait_line, heap, stop, in_heap,downloads_waiting e lock, que são compartilhadas entre as threads criadas. Onde:
- wait_line (dict) - contém uma fila de itens correspondendo a arquivos para download (valor) por domínio (chave).
-
heap (list) - min-heap composto de uma
tupla(último acesso ao domínio, domínio). -
stop (bool) - define se a
threadem execução deve parar de executar. -
in_heap (dict) - registra se um domínio está em
heap. - downloads_waiting (set) - registra itens esperando serem baixados quando a coleta terminar.
-
lock (threading.Lock) - lock que permite as
threadsacessarem as variáveis acima de forma segura.
@staticmethod
def download_consumer(testing=False)Parâmetros:
-
testing (bool) - parâmetro para debugging (default
False).
Método estático responsável por gerenciar o download de itens correspondentes a arquivos, considerando o tempo definido ao baixar arquivos de um mesmo domínio.
Utilizando a variável heap, o método é capaz de saber quando deverá ocorrer o próximo download de arquivo de um determinado domínio. E, ao chegar esse momento, a fila de espera de itens do domínio, disponibilizado por wait_line, informa qual o próximo arquivo será baixado.
A variável heap é gerenciada por esse método para que o tempo estabelecido entre coletas de mesmo domínio sejam respeitadas.
O método process_item é chamado assim que um novo item para download é retirado de wait_line.
@staticmethod
def internal_consumer(wait_line,
heap,
stop,
in_heap,
downloads_waiting,
lock)Parâmetros: As mesmas variáveis definidas em download_consumer.
Método estático responsável por gerenciar que arquivos de sites que foram definidos para serem baixados depois que a coleta das páginas terem sido feitas respeitem essa determinação.
O método verifica se a coleta de determinado site já terminou, isto é, se suas páginas já foram coletadas, e, assim que isso ocorrer, insere na variável heap a informação que o domínio que a coleta feita pertence possui arquivos para serem baixados. Dessa forma, o método internal_consumer terá mais dados a serem processados (pois está sempre a verificar se há novos domínios na variável heap com arquivos a serem baixados), seguindo seu fluxo de execução normal.
@staticmethod
def downloads_waiting_crawl_end(wait_line,
heap,
stop,
in_heap,
downloads_waiting,
lock)Parâmetros: As mesmas variáveis definidas em download_consumer.
Método estático responsável por, a partir de download_source, inserir itens na fila de download de arquvivos de acordo com seu domínio, em wait_line. Além disso, define se os arquivos de uma coleta serão baixados imediatamente, colocando o respectivo domínio em heap ou inserindo-o em downloads_waiting, para que sejam baixados após o fim da coleta das páginas.
@staticmethod
def internal_producer(wait_line,
heap,
stop,
in_heap,
downloads_waiting,
lock,
testing=False)Parâmetros: As mesmas variáveis definidas em download_consumer.
Método estático responsável por baixar um arquivo grande, maior ou igual a 1e9 bytes.
Utiliza a biblioteca wget, para evitar que arquivos grandes fiquem armazenados em memória (ram), os persistindo em disco.
@staticmethod
def download_large_file(item)Parâmetros:
-
item (dict) - contém a
urldo arquivo a ser baixado, o local onde deve ser salvo e uma descrição do mesmo.
Método estático responsável por baixar arquivos pequenos, menor que 1e9 bytes, utilizando a biblioteca requests.
@staticmethod
def download_small_file(item)Parâmetros:
-
item (dict) - contém a
urldo arquivo a ser baixado, o local onde deve ser salvo e uma descrição do mesmo.
Método estático responsável por atualizar o status de download de um item.
@staticmethod
def log_progress(item_id, current, total)Parâmetros:
- item_id (int) - identificador único do item sendo baixado.
- current (int) - quantidade de bytes correntemente baixado.
- total (int) - total de bytes do arquivo sendo baixado.
Método responsável por criar um instância de DownloadDetail, que armazena informações sobre um arquivo sendo baixado, como se foi ou está a espera de ser baixado e seu tamanho.
@staticmethod
def log_item(item)Parâmetros:
-
item (dict) - contém a
urldo arquivo a ser baixado, o local onde deve ser salvo e uma descrição do mesmo.
A classe FileDescriptor é crawlers.file_descriptor.FileDescriptor e é responsável por persistir as descrições de arquivos coletados em arquivos.
Método estático responsável por inserir uma descrição de arquivo ou página coletada na fila para ser persistida em disco.
@staticmethod
def feed_description(destination, description)Parâmetros:
- destination (str) - local da pasta onde ficará armazenado o arquivo com as descrições a serem processadas.
- description (dict) - contém a descrição de um item coletado.
Envia sinal para que a execução do processo em execução do FileDescriptor pare.
@staticmethod
def stop_description_source()Cria um iterator de descrições a serem processadas.
@staticmethod
def description_source(testing=False)Parâmetros:
-
testing (bool) - parâmetro exclusivamente para debugging (default
False).
A partir das descrições obtidas por description_source, chama o método write_description para armazenar cada uma delas em disco.
@staticmethod
def description_consumer(testing=False)Parâmetros:
-
testing (bool) - parâmetro exclusivamente para debugging (default
False).
Escreve a descrição de um item coletado em uma nova linha de um arquivo unificado chamado file_description.jsonl.
@staticmethod
def write_description(item)Parâmetros:
-
item (dict) - contém o local onde o arquivo
file_description.jsonlestá, bem como a descrição de um arquivo baixado.
Uma instância de BaseSpider herda e adiciona funcionalidades a scrapy.Spider e serve de base para os spiders ainda mais personalizados, como para coletas de sites dinâmicos e processamento de formulários.
Método responsável por criar uma instância de BaseSpider. Cria as pastas onde a coleta será salva, bem como arquivos de configuração e logs necessários para o funcionamento de um spider.
def __init__(self, config, *a, **kw)Parâmetros:
- config (dict) - dicionário com a configuração de uma coleta.
-
*a - parâmetros extras repassados a classe pai (
scrapy.Spider). -
**kw - parâmetros extras repassados a classe pai (
scrapy.Spider).
Método responsável por iniciar as URLs de coleta, devendo ser implementado pelas classes filhas.
def start_requests(self)Método implementado pelas classes filhas responsável por processar as respostas HTTP das requisições de coleta, por meio de um objeto scrapy.http.Response. Por exemplo, salvar uma página HTML retornada e/ou descobrir novos links a serem coletados na mesma.
def parse(self, response)Parâmetros:
-
response (scrapy.http.Response) - objeto
scrapy.http.Responseque representa uma resposta HTTP, com dados baixados a espera de serem processados.
Método responsável por gerar as URLs iniciais de coleta. Pode ser a definida pelo usuário como a URL base ou um conujunto de URLs geradas por meio do mecanismo de TEMPLATED URLs, de acordo com a configuração definida para a coleta.
É chamada pelo método start_requests das classes filhas.
def generate_initial_requests(self)[#TODO]
def create_probing_object(self,
base_url,
req_type,
req_body,
resp_handlers)[#TODO]
def create_parameter_generators(self, probe, parameter_handlers)O mecanismo para parar a execução de um spider se trata de uma flag escrita em um arquivo. Esse método verifica se ela está definida para interromper sua execução.
def stop(self)Método responsável por tentar extrair e armazenar tabelas em CSVs obtidos a partir de uma página HTML coletada.
def extract_and_store_csv(self, response, description)Parâmetros:
-
response (scrapy.http.Response) - objeto
scrapy.http.Responseque representa uma resposta HTTP, com dados baixados a espera de serem processados. - description (dict) - contém dados sobre a página HTML coletada, como o local onde está sendo armazenada, para que seja possível acessá-la e criar relacionamentos entre as tabelas extraídas em CSV e sua fonte.
Armazena o conteúdo da página Web coletada, após realizar algumas limpezas na mesma. Também chama o método extract_and_store_csv para extrair possíveis tabelas na página, além de gerar uma descrição da página sendo salva, como quando foi coletada, sua origem, etc.
def store_html(self, response)Parâmetros:
-
response (scrapy.http.Response) - objeto
scrapy.http.Responseque representa uma resposta HTTP, com a página Web baixada.
[#TODO]
def errback_httpbin(self, failure)Ao encontrar um arquivo a ser baixado, o método parser das classes filhas chama esse método para enviar a URL e outras informações sobre o arquivo ao FileDownloader, para que ele seja baixado.
def feed_file_downloader(self, url, response_origin)Parâmetros:
- url (str) - URL do arquivo a ser baixado.
-
response_origin (scrapy.http.Response) - objeto
scrapy.http.Responseque representa uma resposta HTTP, útil para descobrir a origem do arquivo a ser baixado.
Envia a descrição (que são metadados com informações extras do que foi salvo) de um arquivo ou página HTML salva para o método responsável em FileDescriptor.
def feed_file_description(self, destination, content)Parâmetros:
- destination (str) - pasta onde a descrição deverá ser salva.
- content (dict) - a descrição do arquivo ou página em si.
[#TODO]
def extra_config_parser(self, table_attrs)Cria uma hash a partir da URL da requisição feita e do corpo da página coletada. Útil para criar nomes de arquivos únicos.
def hash_response(self, response)Parâmetros:
-
response (scrapy.http.Response) - objeto
scrapy.http.Responseque representa uma resposta HTTP. Necessário para recuperar a URL da página coletada e seu conteúdo.
Herda de BaseSpider e é responsável por realizar coletas em páginas estáticas.
Método responsável por gerar as primeiras URLs a serem coletadas. Na prática, chama o método generate_initial_requests da classe pai gerando para cada uma das URLs geradas, um objeto scrapy.Request, iniciando o processo de coleta.
def start_requests(self)Método responsável por criar um lista de extensões que não devem ser baixados a partir das que devem ser baixadas.
def convert_allow_extesions(self, config)Parâmetros:
- config (dict) - arquivo contendo as configurações de um coletor que está sendo executado.
Método responsável por filtrar URLs que casam com determinada expressão regular. Especialmente útil para que página coletadas fiquem restritas a determinado domínio ou padrão.
def filter_list_of_urls(self, url_list, pattern)Parâmetros:
- url_list (list) - lista de URLs descobertas em uma página coletada sendo processada.
- pattern (str) - expressão regular que determina quais URLs devem ser mantidas.
Realiza requisições do tipo head ao servidor para descobrir o tipo correspondente a URL que terá seu conteúdo baixado.
Caso page_flag seja True, somente URLs que correspondem a páginas HTML serão mantidas. Caso contrário, somente URLs que não correspondem a conteúdo HTML serão mantidas.
FIXME: A extensão do arquivo definido pelo usuário para download não está sendo considerada.
def filter_type_of_urls(self, url_list, page_flag)Parâmetros:
- url_list (list) - lista de URLs descobertas.
- page_flag (bool) - determina se o filtro sob as URLs será considerando que elas correspondem a páginas HTML ou não.
Transforma uma string contendo elementos separados por "," em uma tupla, com somente eles. Isto é, uma string "a,ab,abc" se tornará uma tupla (a, ab, abc).
def preprocess_listify(self, value, default)Parâmetros:
- value (str) - string representando elementos separados por "," a ser transformada em uma tupla.
-
default (any) - caso a string seja inválida (tenha valor
Noneou tenha tamanho nulo), representa o valor padrão a ser retornado.
Realiza um pré-processamento nas configurações do coletor para que o extrator de links possa considerar links que estejam em tags não habituais HTML.
def preprocess_link_configs(self, config)Parâmetros:
- config (dict) - contém dados sobre a configuração de um coletor sendo executado.
Método responsável por extrair links a partir da resposta do servidor, considerando as diferentes configurações definidades pelo usuário. Como a tag onde deve extrair links, bem como configurações de filtragem de URLs para que elas representem somente a páginas HTML.
def extract_links(self, response)Parâmetros:
-
response (scrapy.http.Response) - objeto
scrapy.http.Responseque representa uma resposta HTTP.
Assim como preprocess_link_configs, realiza um pré-processamento na configuração do coletor para que o extrator de links considere definições mais avançadas do usuário, como buscar links em tags não habituais, etc.
def preprocess_download_configs(self, config)Parâmetros:
- config (dict) - contém dados sobre a configuração de um coletor sendo executado.
Extrai links que correspondem a arquivos na página sendo processada, obtida pela resposta HTTP do servidor. É realizado uma filtragem sobre as URLs descobertas para que elas correspondam a um determinado padrão pré-estabelecido pelo usuário e para que os arquivos não sejam páginas HTML.
def extract_files(self, response)Parâmetros:
- config (dict) - contém dados sobre a configuração de um coletor sendo executado.
Método responsável por extrair links de imagens na página sendo processada, obtida pela resposta HTTP do servidor.
def extract_imgs(self, response)Parâmetros:
- config (dict) - contém dados sobre a configuração de um coletor sendo executado.
Método responsável por processar a resposta HTTP do servidor.
Armazena a página HTML retornada, bem como extrai novos links tanto de outras páginas tanto de arquivos baixáveis, chamando os respectivos métodos para sua execução.
def parse(self, response)Parâmetros:
- config (dict) - contém dados sobre a configuração de um coletor sendo executado.
Módulo que serve como uma interface entre o Django e o Scrapy. Converte configurações de coletas definidas pelo usuário por aquelas aceitas pelo Scrapy e inicia e gerencia a execução do spider, além de iniciar os processos para baixar arquivos descobertos durante a coleta e o de escrita das descrições dos mesmos.
Método responsável por iniciar o FileDownloader para que ele fique sempre a procurar por novos itens a serem baixados. Além disso, redireciona a saída padrão e os erros gerados por ele para arquivos.
def file_downloader_process()Realiza os mesmos procedimentos em file_downloader_process, mas para o FileDescriptor.
def file_descriptor_process()Cria as pastas essenciais para a execução de uma coleta, se elas não existirem.
def create_folders(data_path)Parâmetros:
- data_path (str) - local onde as pastas essenciais da coleta está.
Transforma as configurações do coletor em configurações nos padrões do Scrapy.
def get_crawler_base_settings(config)Parâmetros:
- config (dict) - dados da configuração do coletor.
Método responsável por criar um novo spider de coleta, por meio de uma instância de CrawlerProcess, pertencente a scrapy.crawler.
def crawler_process(config)Parâmetros:
- config (dict) - dados da configuração do coletor.
Método que gera identificadores únicos levando em conta o timestamp atual e um valor aleatório.
def gen_key()Cria um novo processo executando crawler_process. Isto é, um spider é iniciado executando em paralelo.
def start_crawler(config)Parâmetros:
- config (dict) - dados da configuração do coletor.
Método responsável por parar uma coleta, ao alterar valores de flags armazenadas em arquivo.
def stop_crawler(instance_id, config)Parâmetros:
- instance_id (str) - identificador único de uma instância de uma coleta sendo realizada.
- config (dict) - dados da configuração do coletor.
Deleta todos os arquivos e pastas de uma coleta.
def remove_crawler(instance_id, are_you_sure=False)Parâmetros:
- instance_id (str) - identificador único de uma instância de um coletor.
- are_you_sure (bool) - útil para checar se o usuário tem certeza que deseja apagar mesmo todos os arquivos.
Quando uma instância de um coletor é alterada (criada, inicializada ou terminada), este método registra em um arquivo de log, chamado instances.json, tais alterações em todas instâncias dele.
def update_instances_info(data_path, instance_id, instance)Parâmetros:
-
data_path (str) - local da pasta onde
instances.jsonestá armazenado. - instance_id (str) - identificador único da instância da coleta.
- instance (dict) - instância da coleta serializada.
Django é a framework responsável por estruturar o backend para que ele possa requisições HTTP dos usuários.
Os arquivos de configuração do projeto Django se encontram no módulo interface. No arquivo settings.py, encontramos as configurações, em si, do Django para o projeto. Já em urls.py, encontramos as rotas das requisições HTTP, que são transferidas para o gerenciador de rotas em main/urls.py. Desse modo, o módulo interface se restringe a manter a estrutura básica do Django, enquanto que a lógica de negócios do servidor foi modularizada em main.
Módulo responsável por implementar a lógica do servidor, como gerenciamento de rotas, modelos (tabelas de dados), API e interface Web.
Django faz uso do conceito ORM, de modo que classes python habituais são mapeadas em tabelas persistidas em um banco de dados. Assim, esse módulo define um série de classes mapeadas em tabelas no banco de dados e que são fundamentais para o sistema.
Todas as classes abaixo herdam direto ou indiretamente de models.Model, de django.db.
Modelo útil para registrar a data de criação e modificação de suas classes filhas.
class TimeStamped(models.Model)Modelo que representa todas as configurações de um coletor em si.
class CrawlRequest(TimeStamped)[#TODO]
class ParameterHandler(models.Model)[#TODO]
class ResponseHandler(models.Model)Armazena o estágio de execução de uma coleta (instância de CrawlRequest), se ela está executando ou não.
class CrawlerInstance(TimeStamped)Armazena detalhes sobre o dowload de um arquivo.
class DownloadDetail(TimeStamped)Implementa a interface Web e a API.