本章内容:
- 内联函数;
- 引用变量;
- 如何按引用传递函数参数;
- 默认参数;
- 函数重载;
- 函数模板;
- 函数模板具体化。
内联函数是C++为提高程序运行速度所做的一项改进。常规函数和内联函数之间的主要区别不在于编写方式,而在于C++编译器如何将它们组合到程序中。 常规函数调用也使程序跳到另一个地址(函数的地址),并在函数结束时返回。
C++内联函数提供了另一种选择。内联函数的编译代码与其他程序代码“内联”起来了。也就是说,编译器将使用相应的函数代码替换函数调用。对于内联代码,程序无需跳到另一个位置处执行代码,再跳回来。因此,内联函数的运行速度比常规函数稍快,但代价是需要占用更多内存。
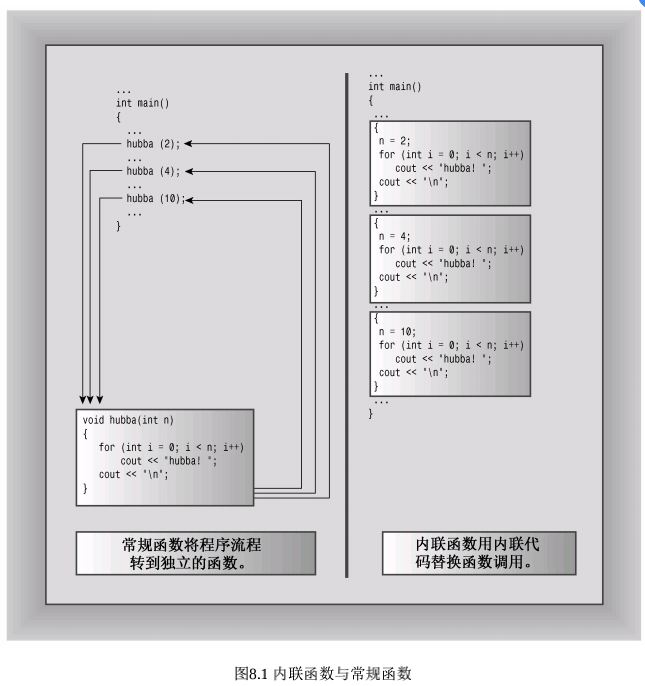
要使用这项特性,必须采取下述措施之一:
- 在函数声明前加上关键字 inline;
- 在函数定义前加上关键字 inline;
内联函数最好都是一些很简单、行数少的函数。
C++新增了一种复合类型——引用变量。引用是已定义的变量的别名(另一个名称)。
C++给&符号赋予另一个含义,将其用来声明引用。例如,要将 rodents作为rats变量的别名,可以这样做:
int rats;
int &rodents = rats; // makes rodents an alias for rats其中,& 不是地址运算符,而是类型标识符的一部分。就像声明中的 char* 指的是指向 char 的指针一样,int & 指的是指向 int 的引用。
将 rodents 加1将影响这两个变量。更准确地说, rodents++ 操作将一共有两个名称的变量加1。
引用看上去很像伪装表示的指针(其中,* 解除引用运算符被隐式理解)。实际上,引用还是不同于指针的。除了表示法不同外,还有其他的差别。例如,差别之一是, 必须在声明引用时将其初始化,而不能像指针那样,先声明,再赋值。

引用更接近const指针,必须在创建时进行初始化,一旦与某个变量关联起来,就将一直效忠于它。也就是说:某个变量的引用是不可更改的。
引用是别名。
引用经常被用作函数参数,使得函数中的变量名成为调用程序中的变量的别名。这种传递参数的方法称为按引用传递。按引用传递允许被调用的函数能够访问调用函数中的变量。C++新增的这项特性是对C语言的超越,C语言只能按值传递。按值传递导致被调用函数使用调用程序的值的拷贝(参见图8.2)。
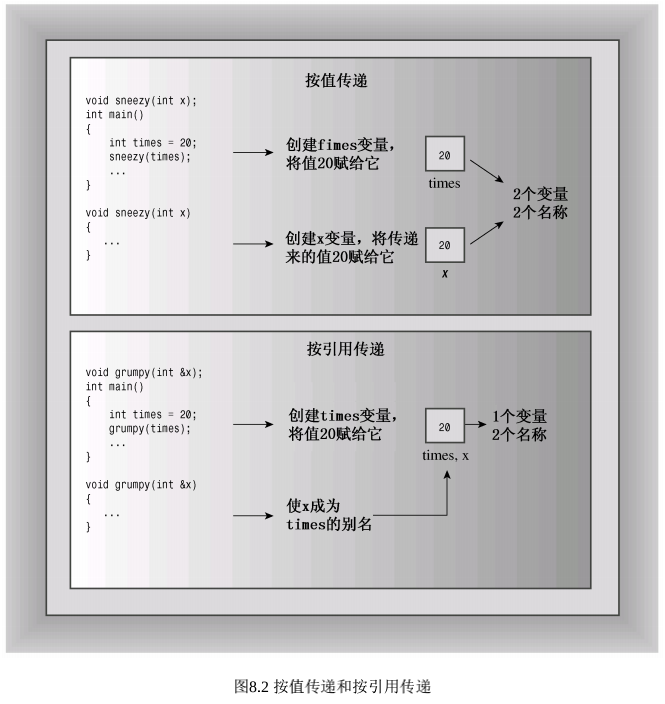
交换函数必须能够修改调用程序中的变量的值。这意味着按值传递变量将不管用,因为函数将交换原始变量副本的内容,而不是变量本身的内容。但传递引用时,函数将可以使用原始数据。另一种方法是,传递指针来访问原始数据。


refcube() 函数修改了 main() 中的 x 值,而 cube() 没有,这提醒我们为何通常按值传递。变量 a 位于 cube() 中,它被初始化为 x 的值,但修改 a 并不会影响 x。但由于 refcube() 使用了引用参数,因此修改 ra 实际上就是修改 x。如果只是让函数使用传递给它的信息,而不对这些信息进行修改,同时又想使用引用,则应使用常量引用。
例如,在这个例子中,应在函数原型和函数头中使用const:
double refcube(const double &ra);如果要编写类似于上述示例的函数(即使用基本数值 类型),应采用按值传递的方式,而不要采用按引用传递的方式。当数据比较大(如结构和类)时,引用参数将很有用。
函数中应尽可能将引用形参声明为 const,这样好处有三个:
- const 可以避免无意中修改数据,从而导致编程错误;
- const 使函数能够处理 const 和非 const 实参,否则只能接受非 const 数据;
- const 引用使函数能够正确生成并使用临时变量。

2.为何要返回引用
下面更深入地讨论返回引用与传统返回机制的不同之处。传统返回机制与按值传递函数参数类似:计算关键字return后面的表达式,并将结果返回给调用函数。从概念上说,这个值被复制到一个临时位置,而 调用程序将使用这个值。
返回引用的函数实际上是被引用的变量的别名。
3.返回引用时需要注意的问题
返回引用时最重要的一点是,应避免返回函数终止时不再存在的内存单元引用。应避免编写如下代码:

该函数返回一个指向临时变量(newguy)的引用,函数运行完毕后 它将不再存在。同样,也应避免返回 指向临时变量的指针。
为避免这种问题,最简单的方法是,返回一个作为参数传递给函数 的引用。作为参数的引用将指向调用函数使用的数据,因此返回的引用 也将指向这些数据。
4.为何将const用于引用返回类型
将类对象传递给函数时,C++通常的做法是使用引用。

使用引用参数的主要原因有两个:
- 能够修改调用函数中的数据对象;
- 通过传递引用而不是整个数据对象,可以提高程序的运行速度。
当数据对象较大时(如结构和类对象),第二个原因最重要。这些也是使用指针参数的原因。这是有道理的,因为引用参数实际上是基于指针的代码的另一个接口。
以下总结使用引用的原则:
- 如果数据对象很小。如内置数据类型或者小型数据结构,则按值传递;
- 如果数据对象是数组,则使用指针,因为这是唯一的选择,并将指针声明为指向 const 的指针;
- 如果数据对象是较大的结构体,则使用 const 指针或者 const 引用,以便提升程序的效率。这样可以节省复制结构体所需的时间和空间;
- 如果数据对象是类对象,则使用 const 引用。类设计的语义常常要求使用引用,这是C++新增这项特性的主要原因。因此,传递类对象参数的标准方式是按引用传递。
对于修改调用函数中数据的函数:
- 如果数据对象是内置数据类型,则使用指针(不使用引用)。看到诸如:
fixit(&x)这样的代码(x是int),则很明显,该函数将要修改x; - 如果数据对象是数组,则只能使用指针;
- 如果数据对象是结构体,则可以使用引用或者指针;
- 如果数据对象是类对象,则(首选)使用引用。
默认参数指的是当函数调用中省略了实参时自动使用的一个值。例如:
char * left(const char *str, int n=1);对于带参数列表的函数,必须从右向左添加默认值。也就是说,要为某个参数设置默认值,则必须为它右边的所有参数提供默认值:
int harpo(int n, int m=4, int j=5); // Valid
int chico(int n, int m=6, int j); // IN-Valid
int groucho(int k=1, int m=2, int n=3); // Valid实参按从左到右的顺序依次被赋给相应的形参,而不能跳过任何参数。
默认参数只在声明函数的时候给出,定义函数时,则不需要给出。


函数多态是C++在C语言的基础上新增的功能。默认参数让我们能够使用不同数目的参数调用同一个函数,而函数多态(函数重载)让我们能够使用多个同名的函数,这称为函数重载,它们完成相同的工作,但使用不同的参数列表。
函数重载的关键是函数的参数列表——也称为函数特征标 (function signature)。
如果两个函数的参数数目和类型相同,同时参数的排列顺序也相同,则它们的特征标相同,而变量名是无关紧要的。 C++允许定义名称相同的函数,条件是它们的特征标不同。

一些看起来彼此不同的特征标是不能共存的。例如,请看下面的两 个原型:
double cube(double x);
double cube(double &x);可能认为可以在此处使用函数重载,因为它们的特征标看起来不同。然而,请从编译器的角度来考虑这个问题。假设有下面这样的代码:
cout << cube(x);参数 x 与 double x 原型和 double &x 原型都匹配,因此编译器无法确定究竟应使用哪个原型。为避免这种混乱,编译器在检查函数特征标时,将把类型引用和类型本身视为同一个特征标。
请记住,是特征标(即,函数特征列表),而不是函数返回类型使得可以对函数进行重载。 例 如,下面的两个声明是互斥的:
long gronk(int n, float m); // same signatures,
double gronk(int n, float m); // hence not allowed因此,C++不允许以这种方式重载gronk( )。返回类型可以不同,但特征标也必须不同。
匹配函数时,并不区分const和非const变量(这就要小心了)。看下面的原型:
void dribble(char *bits); // overloaded
void dribble(const char *cbits); // overloaded
void dabble(char *bits); // not overloaded
void drivel(const char *bits); // not overloaded虽然函数重载很吸引人,但也不要滥用。仅当函数基本上执行相同的任务,但使用不同形式的数据时,才应采用函数重载。
现在的C++编译器实现了C++的另一个新增特性——函数模板。函数模板是通用的函数描述,也就是说,它们使用泛型来定义函数,其中的泛型可用具体的类型(如int或double)替换。通过将类型作为参数传递给模板,可使编译器生成该类型的函数。由于模板允许以泛型(而不是具体类型)的方式编写程序,因此有时也被称为通用编程。由于类型是用参数表示的,因此模板特性有时也被称为参数化类型(parameterized types)。

第一行指出,要建立一个模板,并将类型命名为 AnyType。关键字 template和 typename 是必需的,除非可以使用关键字 class 代替 typename。 另外,必须使用尖括号。类型名可以任意选择(这里为 AnyType),只要遵守C++命名规则即可;许多程序员都使用简单的名称,如 T。
模板并不创建任何函数,而只是告诉编译器如何定义函数。需要交换int的函数时,编译器将按模板 模式创建这样的函数,并用int代替AnyType。同样,需要交换double的函数时,编译器将按模板模式创建这样的函数,并用double代替 AnyType。
最终 的代码不包含任何模板,而只包含了为程序生成的实际函数。使用模板 的好处是,它使生成多个函数定义更简单、更可靠。

typename关键字使得参数AnyType表示类型这一点更为明显;然而,有大量代码库是使用关键字class开发的。在这种上下文中,这两个关键字是等价的。
需要多个对不同类型使用同一种算法的函数时,可使用模板。
- 下面的代码假定定义了赋 值,但如果T为数组,这种假设将不成立;
- 下面的语句假设定义了
<,但如果T为结构,该假设便不成立;另外,为数组名定义了运算符>,但由于数组名为地址,因此它比较的是数组的地址,而这可能不是您希望的。
总之,编写的模板函数很可能无法处理某些类型。另一方面,有时 候通用化是有意义的,但C++语法不允许这样做。
由于C++允许将一个结构赋给另一个结构,因此即使T是一个
job结构,上述代码也适用。然而,假设只想交换salary和floor成员,而不交 换name成员,则需要使用不同的代码,但Swap()的参数将保持不变 (两个job结构的引用),因此无法使用模板重载来提供其他的代码。
- 对于给定的函数名,可以有非模板函数、模板函数和显式具体化模 板函数以及它们的重载版本;
- 显式具体化的原型和定义应以
template<>打头,并通过名称来指出 类型; - 具体化优先于常规模板,而非模板函数优先于具体化和常规模板。
如果有多个原型,则编译器在选择原型时,非模板版本优先于显式具体化和模板版本,而显式具体化优先于使用模板生成的版本。


为进一步了解模板,必须理解术语实例化和具体化。记住,在代码中包含函数模板本身并不会生成函数定义,它只是一个用于生成函数定义的方案。编译器使用模板为特定类型生成函数定义时,得到的是模板实例(instantiation)。
函数调用Swap(i,j)导致编译器生成Swap()的一个实例,该实例使用int类型。模板并非函数定 义,但使用int的模板实例是函数定义。这种实例化方式被称为隐式实例 化(implicit instantiation),因为编译器之所以知道需要进行定义,是 由于程序调用Swap( )函数时提供了int参数。
最初,编译器只能通过隐式实例化,来使用模板生成函数定义,但现在C++还允许显式实例化(explicit instantiation)。这意味着可以直接 命令编译器创建特定的实例,如Swap<int>()。其语法是,声明所需的种类——用<>符号指示类型,并在声明前加上关键字 template:
template void Swap<int>(int, int); // explicit instantiation实现了这种特性的编译器看到上述声明后,将使用Swap()模板生成 一个使用int类型的实例。也就是说,该声明的意思是“使用Swap()模板生成int类型的函数定义“。
与显式实例化不同的是,显式具体化使用下面两个等价的声明之 一:
template <> void Swap<int>(int &, int &);
template <> void Swap(int &, int &);区别在于,这些声明的意思是“不要使用 Swap() 模板来生成函数定 义,而应使用专门为 int 类型显式地定义的函数定义”。这些原型必须有自己的函数定义。显式具体化声明在关键字 template 后包含 <>,而显式实例化没有。
隐式实例化、显式实例化和显式具体化统称为具体化 (specialization)。它们的相同之处在于,它们表示的都是使用具体类 型的函数定义,而不是通用描述。
引入显式实例化后,必须使用新的语法——在声明中使用前缀template和template <>,以区分显式实例化和显式具体化。通常,功能 越多,语法规则也越多。下面的代码片段总结了这些概念:

对于函数重载、函数模板和函数模板重载,C++需要(且有)一个 定义良好的策略,来决定为函数调用使用哪一个函数定义,尤其是有多 个参数时。这个过程称为重载解析(overloading resolution):
- 第1步:创建候选函数列表。其中包含与被调用函数的名称相同的函数和模板函数。
- 第2步:使用候选函数列表创建可行函数列表。这些都是参数数目 正确的函数,为此有一个隐式转换序列,其中包括实参类型与相应 的形参类型完全匹配的情况。例如,使用float参数的函数调用可以 将该参数转换为double,从而与double形参匹配,而模板可以为 float生成一个实例;
- 第3步:确定是否有最佳的可行函数。如果有,则使用它,否则该 函数调用出错。
接下来,编译器必须确定哪个可行函数是最佳的。它查看为使函数 调用参数与可行的候选函数的参数匹配所需要进行的转换。通常,从最 佳到最差的顺序如下所述:
- 完全匹配,但常规函数优先于模板;
- 提升转换(例如,char和shorts自动转换为int,float自动转换为 double);
- 标准转换(例如,int转换为char,long转换为double);
- 用户定义的转换,如类声明中定义的转换。
C++扩展了C语言的函数功能。通过将 inline 关键字用于函数定义, 并在首次调用该函数前提供其函数定义,可以使得C++编译器将该函数视为内联函数。也就是说,编译器不是让程序跳到独立的代码段,以执行函数,而是用相应的代码替换函数调用(相当于复制进去)。只有在函数很短时才能采用内联方式。
引用变量是一种伪装指针,它允许为变量创建别名(另一个名称)。引用变量主要被用作处理结构和类对象的函数的参数。
C++原型让您能够定义参数的默认值。如果函数调用省略了相应的参数,则程序将使用默认值;如果函数调用提供了参数值,则程序将使用这个值(而不是默认值)。只能在参数列表中从右到左提供默认参数。
函数的特征标是其参数列表。程序员可以定义两个同名函数,只要其特征标不同。这被称为函数多态或函数重载。