本文首发公众号:【DASOU】
涉及到的代码部分,可以去我仓库里找,已经1.2k了:
DA-southampton/NLP_abilitygithub.com
文中内容有不同见解大家及时沟通
目录如下:
- 知识蒸馏简单介绍
- Bert 蒸馏到 BiLSTM
- PKD-BERT
- BERT-of-Theseus
- TinyBert
1.1 什么是蒸馏
一般来说,为了提高模型效果,我们可以使用两种方式。一种是直接使用复杂模型,比如你原来使用的TextCNN,现在使用Bert。一种是多个简单模型的集成,这种套路在竞赛中非常的常见。
这两种方法在离线的时候是没有什么问题的,因为不涉及到实时性的要求。但是一旦涉及到到部署模型,线上实时推理,我们需要考虑时延和计算资源,一般需要对模型的复杂度和精度做一个平衡。
这个时候,我们就可以将我们大模型学到的信息提取精华灌输到到小模型中去,这个过程就是蒸馏。
对于一个模型,我们一般关注两个部分:模型架构和模型参数。
简答的说,我们可以把这两个部分当做是我们模型从数据中学习到的信息或者说是知识(当然主要是参数,因为架构一般来说是训练之前就定下来的)
但是这两个部分,对于我们来说,属于黑箱,就是我们不知道里面究竟发生了什么事情。
那么什么东西是我们肉眼可见的呢?从输入向量到输出向量的一个映射关系是可以被我们观测到的。
简单来说,我输入一个example,你输出是一个什么情况我是可以看到的。
区别于标签数据格式 [0,0,1,0],模型的输出结果一般是这样的:[0.01,0.01,0.97,0.01]。
举个比较具象的例子,就是如果我们在做一个图片分类的任务,你的输入图像是一辆宝马,那么模型在宝马这个类别上会有着最大的概率值,与此同时还会把剩余的概率值分给其他的类别。
这些其他类别的概率值一般都很小,但是仍然存在着一些信息,比如垃圾车的概率就会比胡萝卜的概率更高一些。
模型的输出结果含有的信息更丰富了,信息熵更大了,我们进一步的可以把这种当成是一种知识,也就是小模型需要从大模型中学习到的经验。
这个时候我们一般把大模型也就是复杂模型称之为老师网络,小模型也就那我们需要的蒸馏模型称之为学生网络。学生网络通过学习老师网络的输出,进而训练模型,达到比较好的收敛效果。
在前面提到过,卡车和胡萝卜都会有概率值的输出,但是卡车的概率会比胡萝卜大,这种信息是很有用的,它定义了一种丰富的数据相似结构。
上面谈到一个问题,就是不正确的类别概率都比较小,它对交叉熵损失函数的作用非常的低,因为这个概率太接近零了,也就是说,这种相似性存在,但是在损失函数中并没有充分的体现出来。
第一种就是,使用sofmax之前的值,也就是logits,计算损失函数
第二种是在计算损失函数的时候,使用温度参数T,温度参数越高,得到的概率值越平缓。通过升高温度T,我们获取“软目标”,进而训练小模型
其实对于第一种其实是第二种蒸馏方式的的一种特例情况,论文后续有对此进行证明。
这里的温度参数其实在一定程度上和蒸馏这个名词相呼应,通过升温,提取精华,进而灌输知识。
软化公式如下:
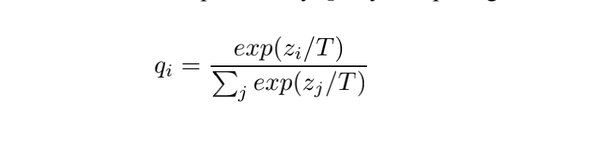
编辑切换为居中
添加图片注释,不超过 140 字(可选)
说一下为什么需要这么一个软化公式。上面我们谈到,通过升温T,我们得到的概率分布会变得比较平缓。
用上面的例子说就是,宝马被识别为垃圾车的概率比较小,但是通过升温之后,仍然比较小,但是没有那么小(好绕口啊)。
也就是说,数据中存在的相似性信息通过升温被放大了,这样在计算损失函数的时候,这个相似性才会被更大的注意到,才会对损失函数产生比较大的影响力。
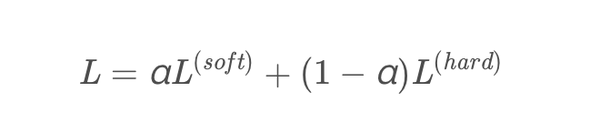
编辑切换为居中
添加图片注释,不超过 140 字(可选)
损失函数是软目标损失函数和硬目标损失函数的结合,一般来说,软目标损失函数设置的权重需要大一些效果会更好一点。
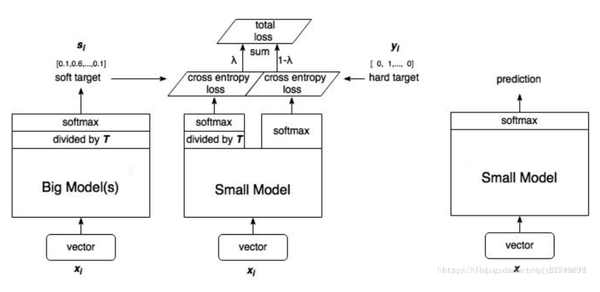
整体的算法示意图如下:
编辑切换为居中
添加图片注释,不超过 140 字(可选)
整体的算法示意图如上所示:
- 首先使用标签数据训练一个正常的大模型
- 使用训练好的模型,计算soft targets。
- 训练小模型,分为两个步骤,首先小模型使用相同的温度参数得到输出结果和软目标做交叉熵损失,其次小模型使用温度参数为1,和标签数据(也就是硬目标)做交叉损失函数。
- 预测的时候,温度参数设置为1,正常预测。
2.1 简单介绍
假如手上有一个文本分类任务,我们在提升模型效果的时候一般有以下几个思路:
- 增大数据集,同时提升标注质量
- 寻找更多有效的文本特征,比如词性特征,词边界特征等等
- 更换模型,使用更加适合当前任务或者说更加复杂的模型,比如FastText-->TextCNN--Bert
...
之后接触到了知识蒸馏,学习到了简单的神经网络可以从复杂的网路中学习知识,进而提升模型效果。
之前写个一个文章是TextCNN如何逼近Bert,当时写得比较粗糙,但是比较核心的点已经写出来。
这个文章脱胎于这个论文:Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
整个训练过程是这样的:
- 在标签数据上微调Bert模型
- 使用三种方式对无标签数据进行数据增强
- Bert模型在无标签数据上进行推理,Lstm模型学习Bert模型的推理结果,使用MSE作为损失函数。
知识蒸馏的目标函数:
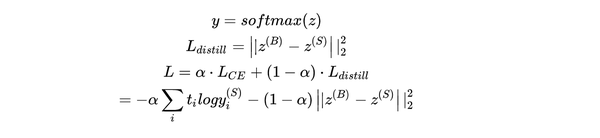
编辑切换为居中
添加图片注释,不超过 140 字(可选)
一般来说,我们会使用两个部分,一个是硬目标损失函数,一个是软目标损失函数,两者都可以使用交叉熵进行度量。
在原论文中,作者在计算损失函数的时候只是使用到了软目标,同时这个软目标并不是使用softmax之前的logits进行MSE度量损失,也就是并没有使用带有温度参数T的sotmax进行归一化。
为了促进有效的知识转移,我们经常需要一个庞大的,未标记的数据集。
三种数据增强的方式:
- Masking:使用概率随机的替换一个单词为[MASK]. 需要注意的是这里替换之后,Bert模型也会输入这个数据的。从直觉上来讲,这个规则可以阐明每个单词对标签的影响。
- POS-guided word replacement.使用概率随机替换一个单词为另一个相同POS的单词。这个规则有可能会改变句子的语义信息。
- n-gram sampling
整个流程是这样的:对于每个单词,如果概率p<,我们使用第一条规则,如果p<,我们使用第二条规则,两条规则互斥,也就是同一个单词只使用两者之间的一个。当对句子中的每个单词都过了一遍之后,我进行第三条规则,之后把整条句子补充道无标签数据集中。
效果图:
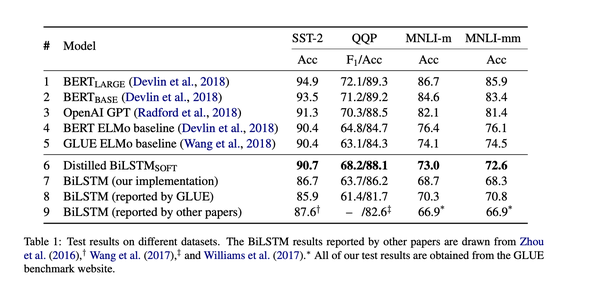
编辑切换为居中
添加图片注释,不超过 140 字(可选)
PKD 核心点就是不仅仅从Bert(老师网络)的最后一层学习知识去做蒸馏,它还另加了一部分,就是从Bert的中间层去学习。
简单说,PKD的知识来源有两部分:中间层+最后输出。
它缓解了之前只用最后softmax输出层的蒸馏方式出现的过拟合而导致泛化能力降低的问题。
接下来,我们从PKD模型的两个策略说起:PKD-Last 和 PKD-Skip。
PKD的本质是从中间层学习知识,但是这个中间层如何去定义,就各式各样了。
比如说,我完全可以定位我只要奇数层,或者我只要偶数层,或者说我只要最中间的两层,等等,不一而足。
那么作者,主要是使用了这么多想法中的看起来比较合理的两种。
PKD-Last,就是把中间层定义为老师网络的最后k层。
这样做是基于老师网络越靠后的层数含有更多更重要的信息。
这样的想法其实和之前的蒸馏想法很类似,也就是只使用softmax层的输出去做蒸馏。但是从感官来看,有种尾大不掉的感觉,不均衡。
另一个策略是 就是PKD-Skip,顾名思义,就是每跳几层学习一层。
这么做是基于老师网络比较底层的层也含有一些重要性信息,这些信息不应该被错过。
作者在后面的实验中,证明了,PKD-Skip 效果稍微好一点(slightly better);
作者认为PKD-Skip抓住了老师网络不同层的多样性信息。而PKD-Last抓住的更多相对来说同质化信息,因为集中在了最后几层。
两种策略的PKD的架构图如下所示,注意观察图,有个细节很容易忽视掉:
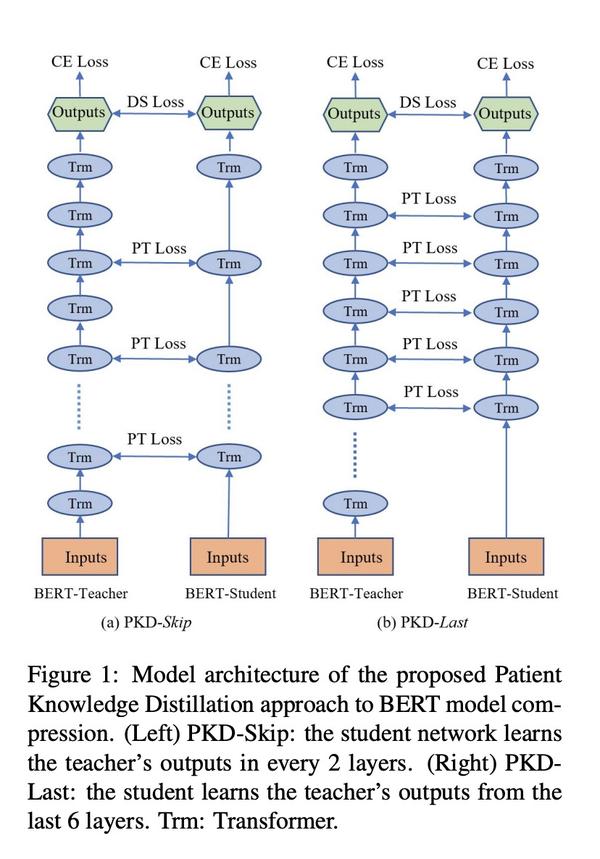
编辑切换为居中
添加图片注释,不超过 140 字(可选)
我们注意看这个图,Bert的最后一层(不是那个绿色的输出层)是没有被蒸馏的,这个细节一会会提到。
这个时候,需要解决一个问题:我们怎么蒸馏中间层?
仔细想一下Bert的架构,假设最大长度是128,那么我们每一层Transformer encoder的输出都应该是128个单元,每个单元是768维度。
那么在对中间层进行蒸馏的时候,我们需要针对哪一个单元?是针对所有单元还是其中的部分单元?
首先,我们想一下,正常KD进行蒸馏的时候,我们使用的是[CLS]单元Softmax的输出,进行蒸馏。
我们可以把这个思想借鉴过来,一来,对所有单元进行蒸馏,计算量太大。二来,[CLS] 不严谨的说,可以看到整个句子的信息。
为啥说是不严谨的说呢?因为[CLS]是不能代表整个句子的输出信息,这一点我记得Bert中有提到。
接下来,我想说一个很小的细节点,对比着看上面的模型架构图:
Bert(老师网络)的最后一层 (Layer 12 for BERT-Base) 在蒸馏的时候是不予考虑;
原因的话,其一可以这么理解,PKD创新点是从中间层学习知识,最后一层不属于中间层。当然这么说有点牵强附会。
作者的解释是最后一层的隐层输出之后连接的就是Softmax层,而Softmax层的输出已经被KD Loss计算在内了。
比如说,K=5,那么对于两种PKD的模式,被学习的中间层分别是:
PKD-Skip: ;
PKD-Last:
还有一个细节点需要注意,就是学生网络的初始化方式,直接使用老师网络的前几层去初始化学生网络的参数。
首先需要注意的是中间层的损失,作者使用的是MSE损失。如下:
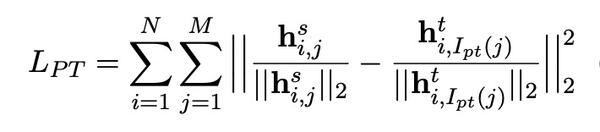
编辑切换为居中
添加图片注释,不超过 140 字(可选)
整个模型的损失主要是分为两个部分:KD损失和中间层的损失,如下:
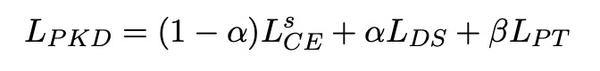
编辑切换为居中
添加图片注释,不超过 140 字(可选)
实验效果可以总结如下:
- PKD确实有效,而且Skip模型比Last效果稍微好一点。
- PKD模型减少了参数量,加快了推理速度,基本是线性关系,毕竟减少了层数
除了这两点,作者还做了一个实验去验证:如果老师网络更大,PKD模型得到的学生网络会表现更好吗?
这个实验我很感兴趣。
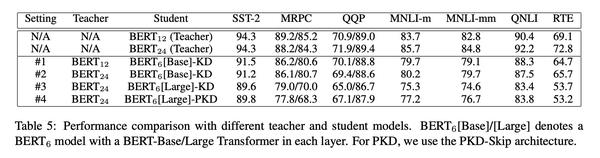
直接上结果图:
编辑切换为居中
添加图片注释,不超过 140 字(可选)
KD情况下,注意不是PKD模型,看#1 和#2,在老师网络增加的情况下,效果有好有坏。这个和训练数据大小有关。
KD情况下,看#1和#3,在老师网络增加的情况下,学生网络明显变差。
作者分析是因为,压缩比高了,学生网络获取的信息变少了。
也就是大网络和小网络本身效果没有差多少,但是学生网络在老师是大网络的情况下压缩比大,学到的信息就少了。
更有意思的是对比#2和#3,老师是大网络的情况下,学生网络效果差。
这里刚开始没理解,后来仔细看了一下,注意#2 的学生网络是,也就是它的初始化是从来的,占了一半的信息。
好的,写到这里
大家好,我是DASOU,今天介绍一下:BERT-of-Theseus
这个论文我觉得还挺有意思,攒个思路。
读完这个文章,BERT-of-Theseus 掌握以下两点就可以了:
- 基于模块替换进行压缩
- 除了具体任务的损失函数,没有其他多余损失函数。
效果的话,与相比,:推理速度 ;模型效果 98%;
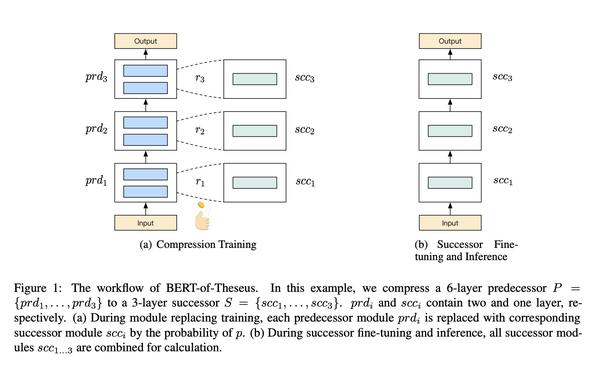
举个例子,比如有一个老师网络是12层的Bert,现在我每隔两层Transformer,替换为学生网络的一层Transformer。那么最后我的学生网络也就变成了6层的小Bert,训练的时候老师网络和学生网络的模块交替训练。
直接看下面这个架构图:
编辑切换为居中
添加图片注释,不超过 140 字(可选)
作者说他是受 Dropout 的启发,仔细想了想还真的挺像的。
我们来说一下这样做的好处。
我刚才说每隔老师网络的两层替换为学生网络的一层。很容易就想到PKD里面,有一个是PKD-Skip策略。
就是每隔几层,学生网络的层去学习老师网络对应层的输出,使用损失函数让两者输出接近,使用的是CLS的输出。
在这里提一下蒸馏/压缩的基本思想,一个最朴素的想法就是让学生网络和老师网络通过损失函数在输出层尽可能的靠近。
进一步的,为了提升效果,可以通过损失函数,让学生网络和老师网络在中间层尽可能的靠近,就像PKD这种。
这个过程最重要的就是在训练的时候需要通过损失函数来让老师网络和学生网络尽可能的接近。
如果是这样的话,问题就来了,损失函数的选取以及各自损失函数之前的权重就需要好好的选择,这是一个很麻烦的事情。
然后我们再来看 BERT-of-Theseus,它就没有这个问题。
它是在训练的时候以概率 来从老师网络某一层和学生网络的某一层选择一个出来,放入到训练过程中。
在这个论文里,老师网络叫做 , 学生网络叫做 ;
对着这个网络架构,我说一下整体训练的过程:
- 在具体任务数据上训练一个 BERT-base 网络作为 ;
- 使用 前六层初始化一个 6层的Bert作为 ;
- 在具体任务数据上,固定 相应权重,以概率(随着steps,线性增加到1),对整个网络(加上 )进行整体的训练。
- 为了让 作为一个整体,单独抽离出来 (其实设置为1就可以了),作为一个单独的个体,在训练数据上继续微调。直至效果不再增加。
简单总结,在训练数据上,老师网络和学生网络共同训练,因为存在概率问题,有的时候是老师网络的部分层加入训练,有的时候是学生网络的部分层加入训练。在这一步训练完成之后,为了保证学生网络作为一个整体(因为在第一步训练的时候大部分情况下学生网络的层都是分开加入训练过程的),在具体任务数据上,对学生网络继续微调,直至效果不再增加。
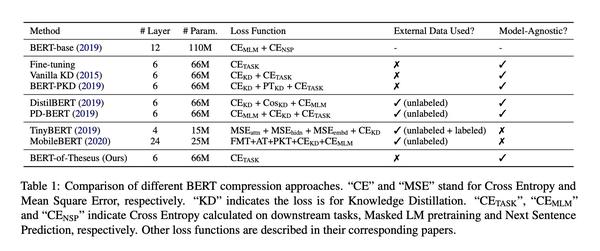
论文提供了一个不同Bert蒸馏方法使用的损失函数的图,值得一看,见下图:
编辑切换为居中
添加图片注释,不超过 140 字(可选)
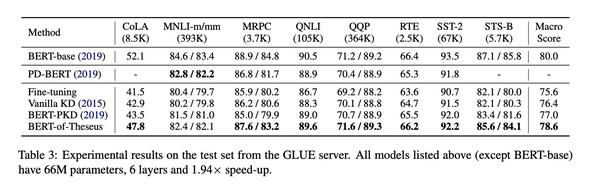
值得注意的是,这里的 应该是选取前六层,在具体任务微调的结果。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
整体来说,BERT-of-Theseus 思路很简单,效果也还不错。
大家好,我是DASOU,今天说一下 TinyBert;
TinyBert 主要掌握两个核心点:
- 提出了对基于 transformer 的模型的蒸馏方式:Transformer distillation;
- 提出了两阶段学习框架:在预训练和具体任务微调阶段都进行了 Transformer distillation(两阶段有略微不同);
下面对这两个核心点进行阐述。
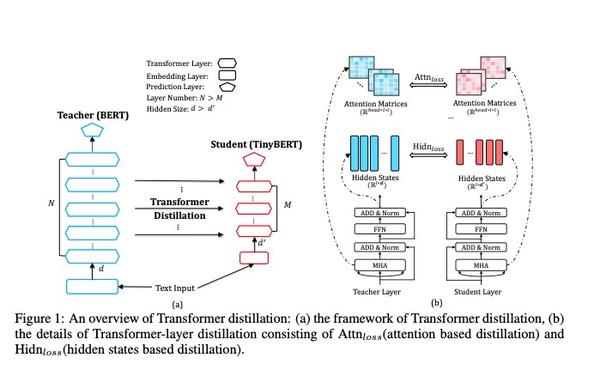
整体架构如下:
编辑切换为居中
添加图片注释,不超过 140 字(可选)
Bert不严谨的来划分,可以分为三个部分:词向量输入层,中间的TRM层,尾端的预测输出层。
在这个论文里,作者把词向量输入层 和中间的TRM层统一称之为中间层,大家读的时候需要注意哈。
Bert的不同层代表了学习到了不同的知识,所以针对不同的层,设定不同的损失函数,让学生网络向老师网络靠近,如下:
- ebedding层的输出
- 多头注意力层的注意力矩阵和隐层的输出
- 预测层的输出
注意力层:
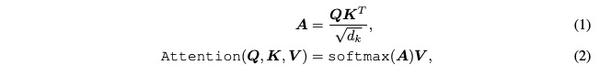
编辑切换为居中
添加图片注释,不超过 140 字(可选)
多头注意力层:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
前馈神经网路:
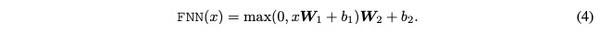
编辑切换为居中
添加图片注释,不超过 140 字(可选)
对 Transformer的蒸馏分为两个部分:一个是注意力层矩阵的蒸馏,一个是前馈神经网络输出的蒸馏。
注意力层矩阵蒸馏的损失函数:
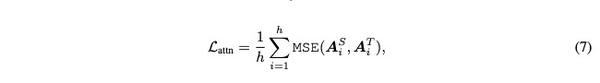
编辑切换为居中
添加图片注释,不超过 140 字(可选)
这里注意两个细节点:
一个是使用的是MSE;
还有一个是,使用的没有归一化的注意力矩阵,见(1),而不是softmax之后的。原因是实验证明这样能够更快的收敛而且效果会更好。
前馈神经网络蒸馏的损失函数
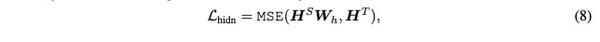
编辑切换为居中
添加图片注释,不超过 140 字(可选)
两个细节点:
第一仍然使用的是MSE.
第二个细节点是注意,学生网路的隐层输出乘以了一个权重矩阵,这样的原因是学生网络的隐层维度和老师网络的隐层维度不一定相同。
所以如果直接计算MSE是不行的,这个权重矩阵也是在训练过程中学习的。
写到这里提一点,其实这里也可以看出来为什么tinybert的初始化没有采用类似PKD这种,而是使用GD过程进行蒸馏学习。
因为我们的tinybert 在减少层数的同时也减少了宽度(隐层的输出维度),如果采用PKD这种形式,学生网络的维度和老师网络的维度对不上,是不能初始化的。
词向量输入层的蒸馏:
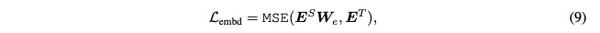
编辑切换为居中
添加图片注释,不超过 140 字(可选)
预测层输出蒸馏:
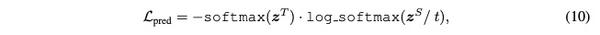
编辑切换为居中
添加图片注释,不超过 140 字(可选)
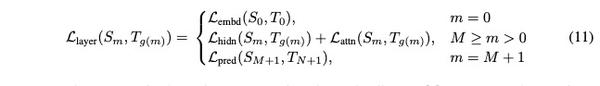
编辑切换为居中
添加图片注释,不超过 140 字(可选)
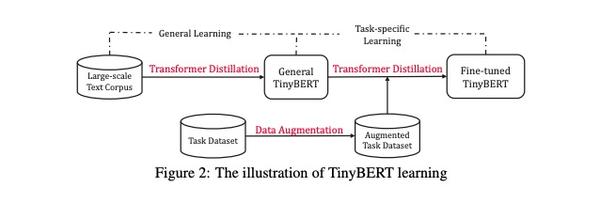
整体架构如图:
编辑切换为居中
添加图片注释,不超过 140 字(可选)
说一下我自己的理解哈,我觉得有两个原因:
首先,就是上文说到的,tinybert不仅降低了层数,也降低了维度,所以学生网络和老师网络的维度是不符的,所以PKD这种初始化方式不太行。
其次,一般来说,比如PKD,学生网络会使用老师网络的部分层进行初始化。这个从直觉上来说,就不太对。
老师网络12层,学到的是文本的全部信息。学生网络是6层,如果使用老师的12层的前6层进行初始化,这个操作相当于认为这前6层代表了文本的全部信息。
当然,对于学生网络,还会在具体任务上微调。这里只是说这个初始化方式不太严谨。
Tiny bert的初始化方式很有意思,也是用了蒸馏的方式。
老师网络是没有经过在具体任务进行过微调的Bert网络,然后在大规模无监督数据集上,进行Transformer distillation。当然这里的蒸馏就没有预测输出层的蒸馏,翻看附录,发现这里只是中间层的蒸馏。
简单总结一下,这个阶段,使用一个预训练好的Bert( 尚未微调)进行了3epochs的 distillation;
TD就是针对具体任务进行蒸馏。
核心点:先进行中间层(包含embedding层)的蒸馏,再去做输出层的蒸馏。
老师网络是一个微调好的Bert,学生网络使用GD之后的tinybert,对老师网络进行TD蒸馏。
TD过程是,先在数据增强之后的数据上进行中间层的蒸馏-10eopchs,learning rate 5e-5;然后预测层的蒸馏3epochs,learning rate 3e-5.
在具体任务数据上进行微调的时候,进行了数据增强。
(感觉怪怪的)
两个细节点:
- 对于 single-piece word 通过Bert找到当前mask词最相近的M个单词;对于 multiple sub-word pieces 使用Glove和Consine找到最相近的M个词
- 通过概率P来决定是否替换当前的词为替换词。
- 对任务数据集中的所有文本数据做上述操作,持续N次。
伪代码如下:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
其实我最关心的一个点就是,数据增强起到了多大的作用。
作者确实也做了实验,如下,数据增强作用还是很大的:
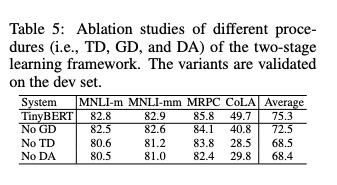
编辑
添加图片注释,不超过 140 字(可选)
我比较想知道的是,在和PKD同等模型架构下,两者的比较,很遗憾,作者好像并没有做类似的实验(或者我没发现)。
这里的tinybert参数如下:
the number of layers M=4, the hidden size d 0=312, the feedforward/filter size d 0 i=1200 and the head number h=12.
先说一下,我读完论文学到的东西:
首先是transformer层蒸馏是如何涉及到的损失函数:
- 注意力矩阵和前馈神经层使用mse;
- 蒸馏的时候注意力矩阵使用未归一化
- 维度不同使用权重矩阵进行转化
其次,维度不同导致不能从老师Bert初始化。GD过程为了解决这个问题,直接使用学生网络的架构从老师网络蒸馏一个就可以,这里并不是重新学一个学生网络。
还有就是数据增强,感觉tinyebert的数据增强还是比较简陋的,也比较牵强,而且是针对英文的方法。
TD过程,对不同的层的蒸馏是分开进行的,先进行的中间层的蒸馏,然后是进行的输出层的蒸馏,输出层使用的是Soft没有使用hard。
这个分过程蒸馏很有意思,之前没注意到这个细节点。
在腾讯的文章中看到这样一句话:
并且实验中,softmax cross-entropy loss 容易发生不收敛的情况,把 softmax 交叉熵改成 MSE, 收敛效果变好,但泛化效果变差。这是因为使用 softmax cross-entropy 需要学到整个概率分布,更难收敛,因为拟合了 teacher BERT 的概率分布,有更强的泛化性。MSE 对极值敏感,收敛的更快,但泛化效果不如前者。
是有道理的,积累一下。
值得看的一些资料:
比 Bert 体积更小速度更快的 TinyBERT - 腾讯技术工程的文章 - 知乎 https://zhuanlan.zhihu.com/p/94359189